Abstract
We propose Adaptive Patch Transformers (APT), a method to accelerate vision transformers (ViTs) by using multiple different patch sizes within the same image. APT reduces the total number of input tokens by using larger patch sizes in more homogeneous image regions, and smaller patches in more complex ones. APT achieves a drastic speedup in ViT inference and training, increasing throughput by 40% on ViT-L and 50% on ViT-H while maintaining downstream performance. It can be applied to a previously fine-tuned ViT and converges in as little as 1 epoch, enabling training on high-resolution images with minimal compute budgets. It also significantly reduces training and inference time with no performance degradation on high-resolution dense visual tasks, achieving up to 30% faster training and inference on visual QA, object detection and semantic segmentation. We will release all code and trained models.
Method Overview
Interactive Demo

Options
Object Detection Examples (EVA02-L-1536)
 Base Tokens: 6240 tokens (97×65) APT Tokens: 3111 tokens -50%
Base Tokens: 6240 tokens (97×65) APT Tokens: 3111 tokens -50%  Base Tokens: 6144 tokens (97×64) APT Tokens: 5205 tokens -15%
Base Tokens: 6144 tokens (97×64) APT Tokens: 5205 tokens -15%  Base Tokens: 6336 tokens (96×66) APT Tokens: 3297 tokens -48%
Base Tokens: 6336 tokens (96×66) APT Tokens: 3297 tokens -48%  Base Tokens: 6144 tokens (97×64) APT Tokens: 5235 tokens -15%
Base Tokens: 6144 tokens (97×64) APT Tokens: 5235 tokens -15%  Base Tokens: 6240 tokens (97×65) APT Tokens: 3843 tokens -38%
Base Tokens: 6240 tokens (97×65) APT Tokens: 3843 tokens -38%  Base Tokens: 6912 tokens (96×72) APT Tokens: 5754 tokens -17%
Base Tokens: 6912 tokens (96×72) APT Tokens: 5754 tokens -17%  Base Tokens: 6240 tokens (97×65) APT Tokens: 4077 tokens -34%
Base Tokens: 6240 tokens (97×65) APT Tokens: 4077 tokens -34%  Base Tokens: 6144 tokens (97×64) APT Tokens: 4284 tokens -30%
Base Tokens: 6144 tokens (97×64) APT Tokens: 4284 tokens -30% Semantic Segmentation Examples (EVA02-L-640)
 Base Tokens: 2440 tokens (61×40) APT Tokens: 2009 tokens -18%
Base Tokens: 2440 tokens (61×40) APT Tokens: 2009 tokens -18%  Base Tokens: 1600 tokens (40×40) APT Tokens: 580 tokens -64%
Base Tokens: 1600 tokens (40×40) APT Tokens: 580 tokens -64%  Base Tokens: 2160 tokens (54×40) APT Tokens: 1701 tokens -21%
Base Tokens: 2160 tokens (54×40) APT Tokens: 1701 tokens -21%  Base Tokens: 1600 tokens (40×40) APT Tokens: 823 tokens -49%
Base Tokens: 1600 tokens (40×40) APT Tokens: 823 tokens -49%  Base Tokens: 1600 tokens (40×40) APT Tokens: 1123 tokens -30%
Base Tokens: 1600 tokens (40×40) APT Tokens: 1123 tokens -30% 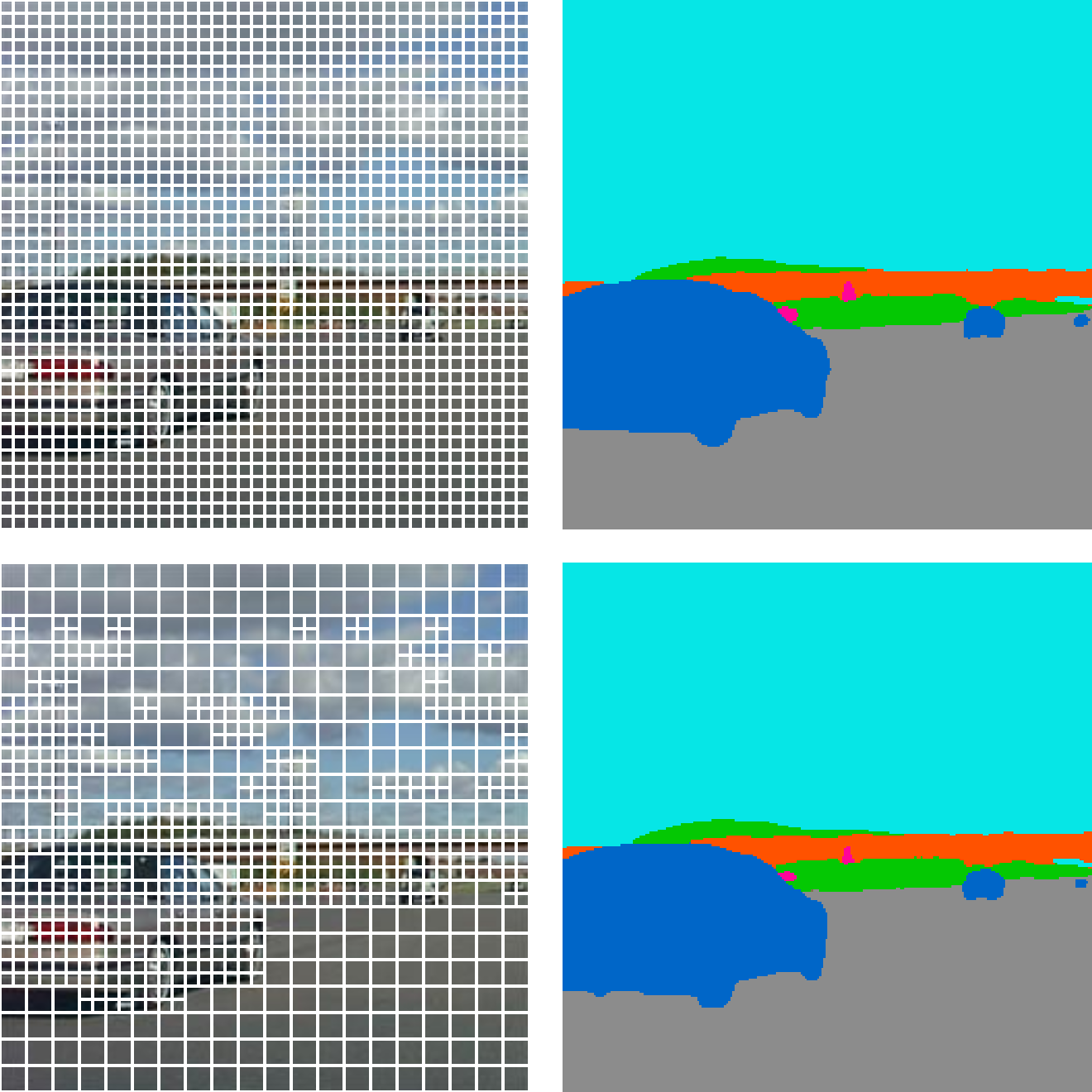 Base Tokens: 1600 tokens (40×40) APT Tokens: 856 tokens -46%
Base Tokens: 1600 tokens (40×40) APT Tokens: 856 tokens -46%  Base Tokens: 2160 tokens (54×40) APT Tokens: 1638 tokens -24%
Base Tokens: 2160 tokens (54×40) APT Tokens: 1638 tokens -24%  Base Tokens: 2560 tokens (64×40) APT Tokens: 1894 tokens -26%
Base Tokens: 2560 tokens (64×40) APT Tokens: 1894 tokens -26%  Base Tokens: 1600 tokens (40×40) APT Tokens: 1030 tokens -36%
Base Tokens: 1600 tokens (40×40) APT Tokens: 1030 tokens -36%  Base Tokens: 2160 tokens (54×40) APT Tokens: 1527 tokens -29%
Base Tokens: 2160 tokens (54×40) APT Tokens: 1527 tokens -29%  Base Tokens: 2200 tokens (55×40) APT Tokens: 1610 tokens -27%
Base Tokens: 2200 tokens (55×40) APT Tokens: 1610 tokens -27% 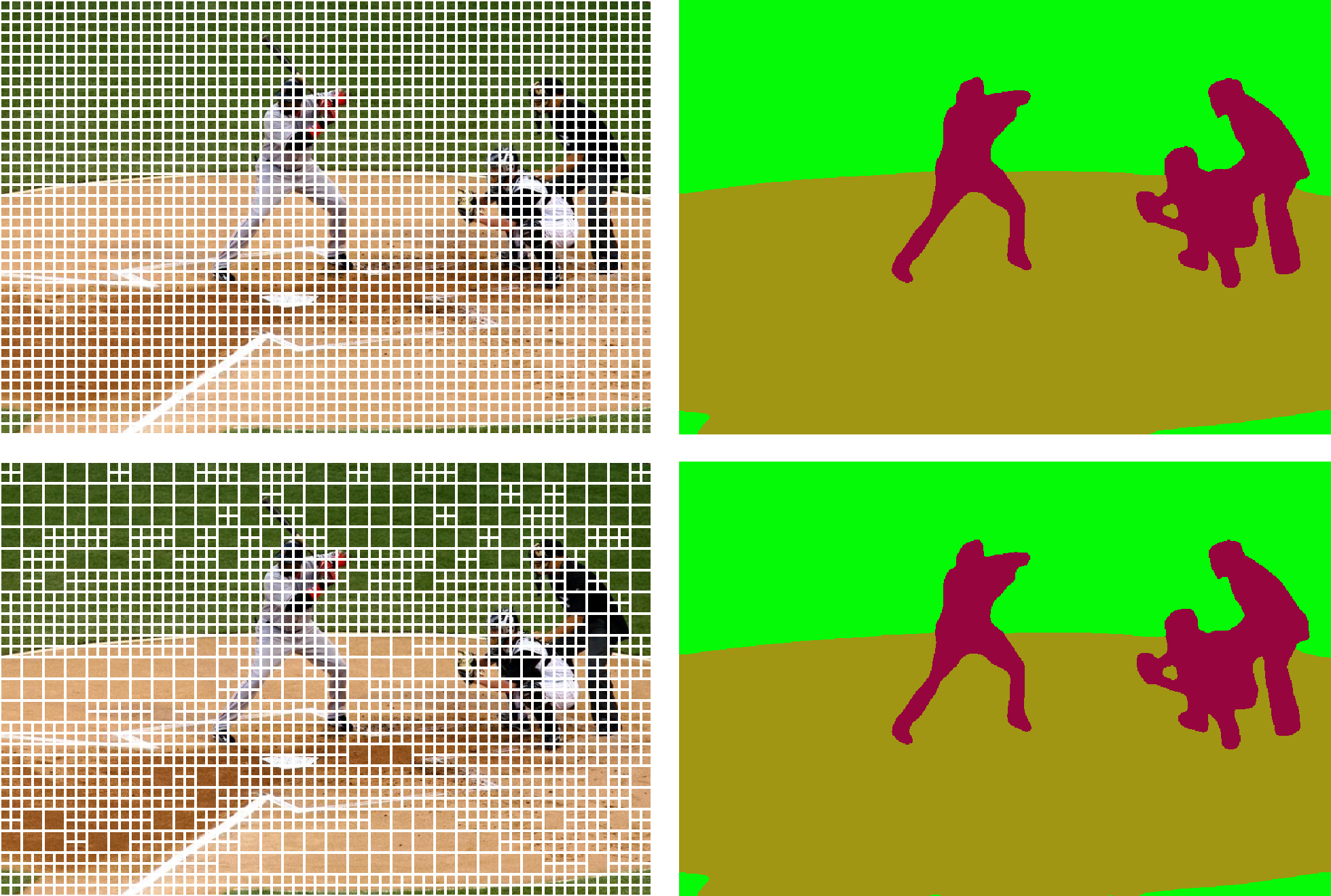 Base Tokens: 2400 tokens (60×40) APT Tokens: 1773 tokens -26%
Base Tokens: 2400 tokens (60×40) APT Tokens: 1773 tokens -26% BibTeX
@article{choudhury2025apt,
title={Accelerating Vision Transformers with Adaptive Patch Sizes},
author={Choudhury, Rohan and Kim, JungEun and Park, Jinhyung and Yang, Eunho and Jeni, L{\'a}szl{\'o} A. and Kitani, Kris M.},
journal={arXiv preprint arXiv:2510.18091},
year={2025},
url={https://arxiv.org/abs/2510.18091},
doi={10.48550/arXiv.2510.18091}
}