Inspired by video compressors, RLT efficiently identifies patches from the input video that are repeated, and prunes them from the input. It then uses a duration encoding to tell the transformer what patches were removed. For all the videos on this page, the lighter colored patches represent patches that are masked out. These semantically correspond to parts of the video that are not moving and are almost exactly repeated over time.
Method Overview
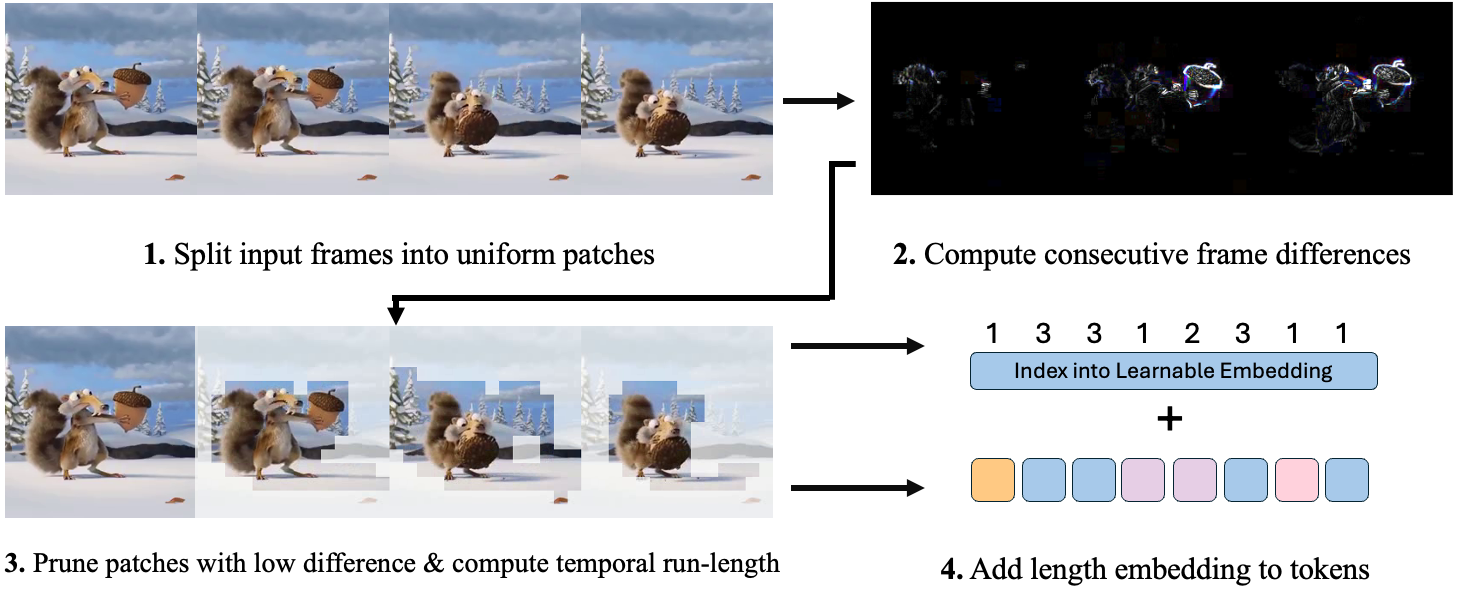
RLT works by first comparing the input frames to find redundant patches. We deem two patches to be redundant if the the mean L1 norm of their pixel difference is less than a input threshold. For every patch in each frame, we compare with the following frame, and remove the patches that are similar enough. Once those are removed, we compute the "run-length", or number of consecutive patches in a spatial location that were removed. This represents the 'duration' of the token, and is expressed to the transformer via the length embedding. We display this in the below plot through a toy example:
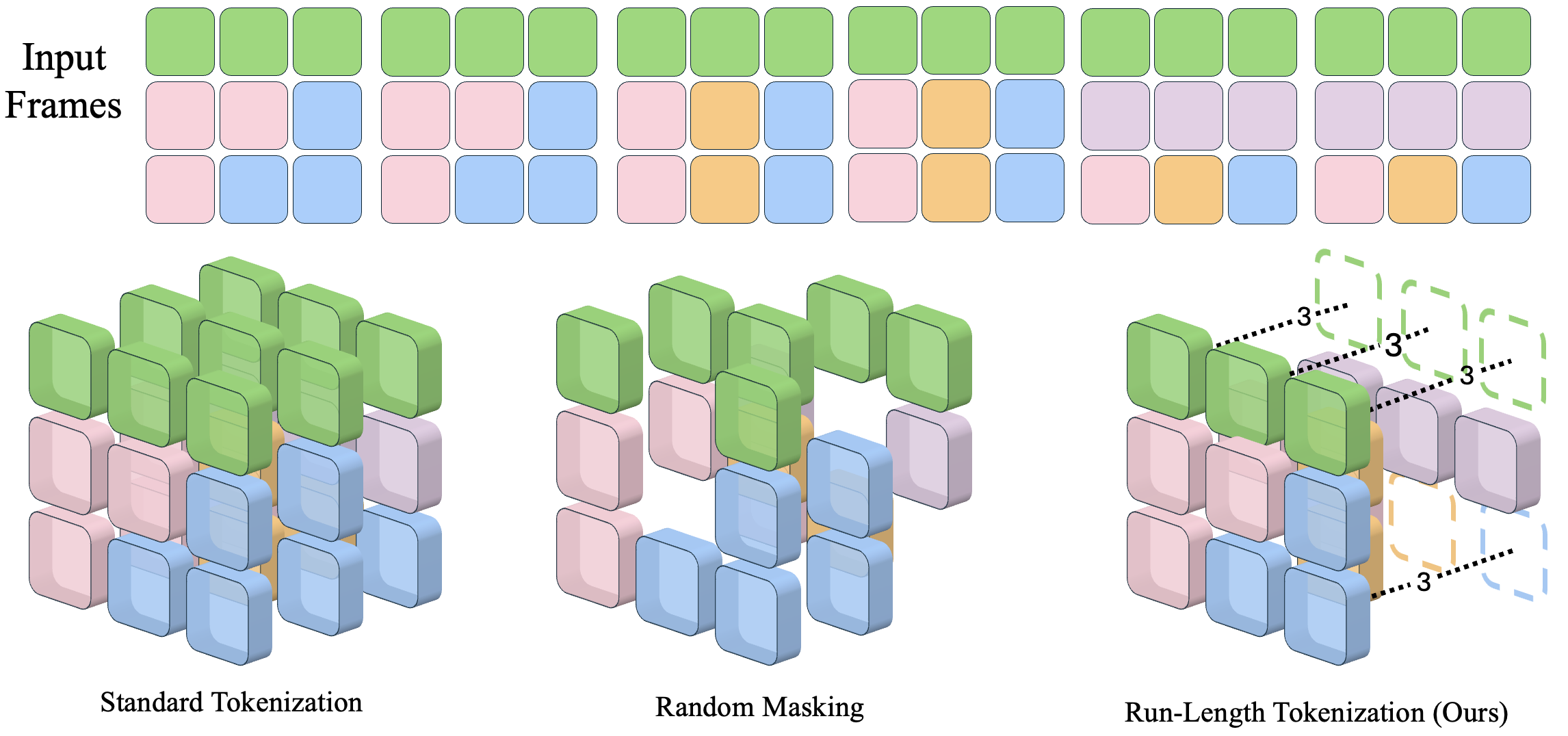
In this example, each token consists of two consecutive patches in the same spatial location. Repeated tokens over time are replaced with a single token at the beginning of the sequence, and the duration of the token is encoded via the length embedding. For example, the green tokens on the top row all have a duration of 3. This enables RLT to remove 6 tokens from the input, while compensating for the loss of information. An added benefit of RLT is that it does not require running the model to determine the new length of the input. This enables us to avoid having to pad examples, and can use block-diagonal attention masks to efficiently run attention on large batches of examples with no overhead. This enables us to make the most of the token reduction, while other methods typically show lower theoretical GFLOPS but no wall-clock speedup in pracice.